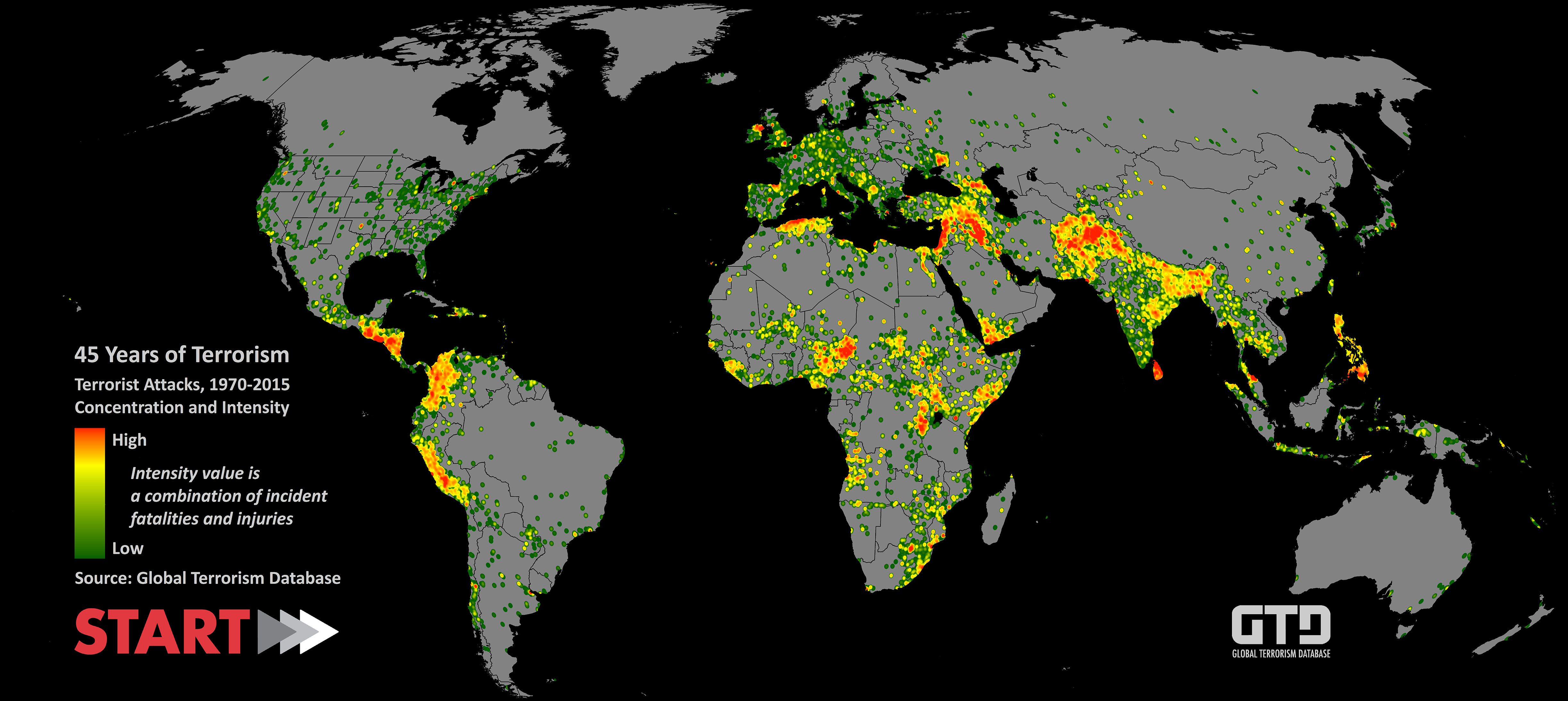

Global Terrorism Database (1970 - 2015) Preliminary Data Cleaning
Introduction
In the coming three posts, I will show my explrative data analytics work on the Global Terrorism Database (GTD), a database maintained by the National Consortium for the Study of Terrorism (START) at the University of Maryland, College Park. I used the version published on Kaggle in early 2017 for this project, which covers terrorist attacks happened between 1970 and 2015. (This database has been updated in July 2017 to include incidents in 2016.)
All relevant codes used to generate visuals in these three posts can be found at my GitHub GTD repository.
From the GTD explorative analysis, I hoped to gather some insights from the 45 years of data on terrorism and global public safety. More specifically, I intend to answer the following questions:
- Since 1970, how many terrorist attacks have occurred in the United States? How does it look from a global scale?
- Of those attacks happened in the U.S., what are their attack methods and targets?
- How did these attacks change over time? Where did these attacks happen and what were their motives?
I selected this dataset, and these questions in particular, because of their relevancy to current debates. I am interested in finding out where are the significant terrorist threats coming from and how have these threats changed over the years. The database relies on materials that are publicly available and unclassified, covering terrorism incidents that happened between 1 January 1970 and 31 December 2015, with more recent incidents not published by START yet. As of now, the database includes over 2,600 terrorist attacks which have occurred in the United States. Additionally, it includes information about the target, perpetrator, and motivations. This makes the dataset ideal for my purposes.
In this post, I will step through the data cleaning and preprocessing techniques with R programming on the GTD database to make it ready for explorative data analysis and visualizations.
Load database into R environment
First, I will load the flat file from the original GTD database into an dataframe object.
# Load data
db <- read.csv("globalterrorismdb_0616dist.csv", na.string = c("", "NA", " "))
class(db)
## [1] "data.frame"
This dataframe object contains 156772 incidents from the year of 1970 to the year of 2015, with 137 variables. There are 2693 incidents that happened in the U.S., while around 2164 cases are surely terrorism incidents. Since our core question is where the terrorism attacks in the US originate from, we will make these cases our primary focus on this project and trim down the incidents and variables accordingly.
Clean up data type and format based on GTD Code Book
# Create a dataframe for attacks in the US
dt <- db %>%
dplyr::select(eventid, iyear, imonth, iday, extended, summary, doubtterr, multiple, related, country_txt, region_txt, provstate, latitude, longitude, attacktype1_txt, attacktype2_txt, attacktype3_txt, success, suicide, weaptype1_txt, weaptype2_txt, weaptype3_txt, weaptype4_txt, target1, targtype1_txt, natlty1_txt, target2, targtype2_txt, natlty2_txt, target3, targtype3_txt,natlty3_txt, gname, gname2, gname3, guncertain1, guncertain2, guncertain3, nperps, nperpcap, claimed, compclaim, motive, nkill, nkillter, nwound, nwoundte, property, propextent, ishostkid, nhostkid, INT_LOG, INT_IDEO, INT_MISC, INT_ANY) %>%
filter(doubtterr == 0, country_txt == "United States")
# Create a dataframe with same structure for the world, for reference purpose
dt_w <- db %>%
dplyr::select(eventid, iyear, imonth, iday, extended, summary, doubtterr, multiple, related, country_txt, region_txt, provstate, latitude, longitude, attacktype1_txt, attacktype2_txt, attacktype3_txt, success, suicide, weaptype1_txt, weaptype2_txt, weaptype3_txt, weaptype4_txt, target1, targtype1_txt, natlty1_txt, target2, targtype2_txt, natlty2_txt, target3, targtype3_txt,natlty3_txt, gname, gname2, gname3, guncertain1, guncertain2, guncertain3, nperps, nperpcap, claimed, compclaim, motive, nkill, nkillter, nwound, nwoundte, property, propextent, ishostkid, nhostkid, INT_LOG, INT_IDEO, INT_MISC, INT_ANY) %>%
filter(doubtterr == 0) # 217 is the country code for United States
The water-downed version of the database contains 2164 incidents and 55 variables.
Check out the variables
I selected the most relevant details in the database for my EDA purposes. For each incident, the database includes variables that describe the incidents from nine different aspects:
| Incident Aspect | Variable Names | Incident Aspect | Variable Names |
|---|---|---|---|
| GTD ID and Date | eventid, iyear, imonth, iday, extended | Target/Victim Information | target1, targtype1_txt, natlty1_txt, target2, targtype2_txt, natlty2_txt, target3, targtype3_txt, natlty3_txt |
| Incident Information | summary, doubtterr, multiple, related | Perpetrator Information | gname, gname2, gname3, guncertain1, guncertain2, guncertain3, nperps, nperpcap, claimed, compclaim |
| Incident Location | country_txt, region_txt, provstate, latitude, longitude | Casualties and Consequences | nkill, nkillter, nwound, nwoundte, property, propextent, ishostkid, nhostkid |
| Attack Information | attacktype1_txt, attacktype2_txt, attacktype3_txt, success, suicide | Additional Information and Sources | INT_LOG, INT_IDEO, INT_MISC, INT_ANY |
| Weapon Information | weaptype1_txt, weaptype2_txt, weaptype3_txt, weaptype4_txt |
Please refer to the GTD code book if you are interested to know more about each variable listed here.
Double check variable types and deal with data quality
My next step is to make sure the data I am using are of consistent format. I will also create a few extra variables to fulfill following steps in data exploration.
After a quick glimpse at the data, I should conduct the following changes to the dataframe:
# Change variables with strings back to character vector
dt$summary <- as.character(dt$summary)
dt$target1 <- as.character(dt$target1)
dt$target2 <- as.character(dt$target2)
dt$target3 <- as.character(dt$target3)
# Trim factor variables to only have included levels
dt <- dt %>% dmap_if(is.factor, fct_drop)
# Recode -9 and -99 as NA in the dataframe
dt[dt == -9 | dt == -99] <- NA
# Recode factors "." and "Unknown" into NA in the factors
for (i in 1:ncol(dt)){
if (is.factor(dt[,i])){
levels(dt[,i]) <- sub("^.$", NA, levels(dt[,i]))
levels(dt[,i]) <- sub("Unknown", NA, levels(dt[,i]))
}
}
# Run the same codes on the world reference dataframe
# Change variables with strings back to character vector
dt_w$summary <- as.character(dt_w$summary)
dt_w$target1 <- as.character(dt_w$target1)
dt_w$target2 <- as.character(dt_w$target2)
dt_w$target3 <- as.character(dt_w$target3)
# Trim factor variables to only have included levels
dt_w <- dt_w %>% dmap_if(is.factor, fct_drop)
# Recode -9 and -99 as NA in the dataframe
dt_w[dt_w == -9 | dt_w == -99] <- NA
# Recode factors "." and "Unknown" into NA in the factors
for (i in 1:ncol(dt_w)){
if (is.factor(dt_w[,i])){
levels(dt_w[,i]) <- sub("^.$", NA, levels(dt_w[,i]))
levels(dt_w[,i]) <- sub("Unknown", NA, levels(dt_w[,i]))
}
}
Now that the data is cleaned and unified, I will generate a date feature that combines the iyear, imonth, and iday features in the dateframe for easier usage in date slicing. Since the dataframe has 28 incidents that does not have a clarified day, I will assign 1 to these incidents as an approximation in order to create a complete date object. (This won’t be a problem for my data exploration since I will only be using year and month on such a wide time span.)
# Replace unknown days (0 according to the code book) with 1
dt$iday <- as.integer(gsub(0, 1, dt$iday))
# Create a new variable "idate"
dt$idate <- as.Date(paste0(dt$iyear,
stringr::str_pad(as.character(dt$imonth), width = 2, side = "left", pad = "0"),
stringr::str_pad(as.character(dt$iday), width = 2, side = "left", pad = "0")), "%Y%m%d")
# There are 23 incidents where the date object fails to show
# a closer look finds that these are incidents where iday = 31
# when the month actually won't have 31 days.
# We will treat these idays as 30, i.e. end of the month
dt$iday[is.na(dt$idate)] <- 30
dt$idate <- as.Date(paste0(dt$iyear,
stringr::str_pad(as.character(dt$imonth), width = 2, side = "left", pad = "0"),
stringr::str_pad(as.character(dt$iday), width = 2, side = "left", pad = "0")), "%Y%m%d")
# Repeat Same Step for the World Refernce Dataframe
# Replace unknown days (0 according to the code book) with 1
dt_w$iday <- as.integer(gsub(0, 1, dt_w$iday))
# Create a new variable "idate"
dt_w$idate <- as.Date(paste0(dt_w$iyear,
stringr::str_pad(as.character(dt_w$imonth), width = 2, side = "left", pad = "0"),
stringr::str_pad(as.character(dt_w$iday), width = 2, side = "left", pad = "0")), "%Y%m%d")
# There are 23 incidents where the date object fails to show
# a closer look finds that these are incidents where iday = 31
# when the month actually won't have 31 days.
# We will treat these idays as 30, i.e. end of the month
dt_w$iday[is.na(dt_w$idate)] <- 30
dt_w$idate <- as.Date(paste0(dt_w$iyear,
stringr::str_pad(as.character(dt_w$imonth), width = 2, side = "left", pad = "0"),
stringr::str_pad(as.character(dt_w$iday), width = 2, side = "left", pad = "0")), "%Y%m%d")
The polished dataframe should have variables that look like below:
#Take a quick look at the variables
glimpse(dt)
## Observations: 2,164
## Variables: 56
## $ eventid <dbl> 197001010002, 197001020003, 197001030001, 1970...
## $ iyear <int> 1970, 1970, 1970, 1970, 1970, 1970, 1970, 1970...
## $ imonth <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...
## $ iday <dbl> 1, 2, 3, 9, 12, 12, 13, 14, 19, 19, 19, 22, 25...
## $ extended <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ summary <chr> "1/1/1970: Unknown African American assailants...
## $ doubtterr <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ multiple <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ related <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ country_txt <fctr> United States, United States, United States, ...
## $ region_txt <fctr> North America, North America, North America, ...
## $ provstate <fctr> Illinois, Wisconsin, Wisconsin, Michigan, New...
## $ latitude <dbl> 37.00511, 43.07659, 43.07295, 42.33169, 40.610...
## $ longitude <dbl> -89.17627, -89.41249, -89.38669, -83.04792, -7...
## $ attacktype1_txt <fctr> Armed Assault, Facility/Infrastructure Attack...
## $ attacktype2_txt <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, Armed...
## $ attacktype3_txt <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ success <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1...
## $ suicide <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ weaptype1_txt <fctr> Firearms, Incendiary, Incendiary, Incendiary,...
## $ weaptype2_txt <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, Firea...
## $ weaptype3_txt <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ weaptype4_txt <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ target1 <chr> "Cairo Police Headquarters", "R.O.T.C. offices...
## $ targtype1_txt <fctr> Police, Military, Government (General), Gover...
## $ natlty1_txt <fctr> United States, United States, United States, ...
## $ target2 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA...
## $ targtype2_txt <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ natlty2_txt <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ target3 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA...
## $ targtype3_txt <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ natlty3_txt <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ gname <fctr> Black Nationalists, New Year's Gang, New Year...
## $ gname2 <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ gname3 <fctr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ guncertain1 <int> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0...
## $ guncertain2 <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA...
## $ guncertain3 <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA...
## $ nperps <int> NA, 1, 1, NA, NA, NA, NA, NA, 3, 2, NA, NA, NA...
## $ nperpcap <dbl> NA, 1, 1, NA, NA, NA, NA, NA, NA, 2, NA, NA, N...
## $ claimed <int> 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ compclaim <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA...
## $ motive <fctr> To protest the Cairo Illinois Police Deparmen...
## $ nkill <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ nkillter <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ nwound <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 2, 0, 0, 0...
## $ nwoundte <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ property <int> 1, 1, 1, 1, 1, NA, 1, 1, 1, 0, 1, 1, 1, 1, 0, ...
## $ propextent <int> 3, 3, 3, 3, 3, 4, 3, 3, 3, NA, 3, 3, 3, 3, NA,...
## $ ishostkid <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ nhostkid <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA...
## $ INT_LOG <int> NA, 0, 0, NA, NA, NA, NA, NA, NA, NA, NA, NA, ...
## $ INT_IDEO <int> NA, 0, 0, NA, NA, NA, NA, NA, NA, NA, NA, NA, ...
## $ INT_MISC <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ INT_ANY <int> NA, 0, 0, NA, NA, NA, NA, NA, NA, NA, NA, NA, ...
## $ idate <date> 1970-01-01, 1970-01-02, 1970-01-03, 1970-01-0...

Leave a Comment